Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Hyland Connect
- Platform
- Alfresco
- Alfresco Blog
- Troubleshooting slow queries - PostgreSQL
alxgomz

Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-18-2018
12:33 PM
One of the recurring issues we see raised by customers are regarding slow SQL queries.
Most of the time those are first witnessed within the Share UI page load time or through long running CMIS queries.
Pinpointing those queries can be a pain and this blog post aims at providing some helps in the troubleshooting process.
We will cover:
- Things to check in the first place
- Different ways of getting informations on the query execution time
- Isolating where the RDBMS is spending more time.
- Present some tools and configuration to help proactively track this kind of issues.
We hope this content will be useful in real life but really having a DBA who takes care of the Alfresco database is the best you can offer to your Alfresco application!
Preliminary checks
Before blaming the database, it's always a good thing to check that the database engine has appropriate resources in order to deliver good performances. You cannot expect any DB engine to perform well with Alfresco with limited resources. For PostgreSQL there are plenty of resource on the web about sizing a database cluster (here I use cluster in the PostgreSQL meaning, which is different from what we call a cluster in Alfresco).
Latency
Network latency can be a performance killer. Opening connections is a quite intensive process and if your network is lame, it will impact the application. Simple network tests can make you sure the network is delivering a good enough transport layer. The ping utility is really the first thing to look at. A ping test between Alfresco and its DB server must show a latency under 1ms on a directly connected network (ethernet Gb), or between 1 & 5 ms if you DB server and the Alfresco server are connected through routed networks. Definitely a value around or above 10ms is not what Alfresco expects from a DB server.
alxgomz@alfresco:~$ ping -c 5 -s500 192.168.0.68
PING 192.168.0.68 (192.168.0.68) 500(528) bytes of data.
508 bytes from 192.168.0.68: icmp_seq=1 ttl=64 time=0.436 ms
508 bytes from 192.168.0.68: icmp_seq=2 ttl=64 time=0.364 ms
508 bytes from 192.168.0.68: icmp_seq=3 ttl=64 time=0.342 ms
508 bytes from 192.168.0.68: icmp_seq=9 ttl=64 time=0.273 ms
508 bytes from 192.168.0.68: icmp_seq=10 ttl=64 time=0.232 ms
--- 192.168.0.68 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 8997ms
rtt min/avg/max/mdev = 0.232/0.329/0.436/0.066 msSome more advanced utilities allow to send TCP packets which are more representative to the actual time spent on opening a tcp session (again you should not have values above 10 ms):
alxgomz@alfresco:~$ sudo hping3 -s 1025 -p 80 -S -c 5 192.168.0.68
HPING 192.168.0.68 (eth0 192.168.0.68): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.68 ttl=64 DF id=0 sport=80 flags=SA seq=0 win=29200 rtt=3.5 ms
len=44 ip=192.168.0.68 ttl=64 DF id=0 sport=80 flags=SA seq=1 win=29200 rtt=3.4 ms
len=44 ip=192.168.0.68 ttl=64 DF id=0 sport=80 flags=SA seq=2 win=29200 rtt=3.4 ms
len=44 ip=192.168.0.68 ttl=64 DF id=0 sport=80 flags=SA seq=3 win=29200 rtt=3.6 ms
len=44 ip=192.168.0.68 ttl=64 DF id=0 sport=80 flags=SA seq=4 win=29200 rtt=3.5 ms
--- 192.168.0.68 hping statistic ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max = 3.4/3.5/3.6 msOverall network quality is also something to check. If your network devices spend their time reassembling unordered packets or retransmiting them the application performances will suffer from it. This can be checked by taking a network dump during query execution and opening it using wireshark.
In order to take the dump you can use the following tcpdump command:
alxgomz@alfresco:~$ tcpdump -ni any port 5432 and host 192.168.0.68 -w /tmp/pgsql.pcap
Opening it in wireshark should give you an idea very quickly. If you see a dump with a lot of red/black lines then it might be an issue and needs further investigations (those lines are colored this way if wireshark has the right syntaxic coloration rules applied).
RDBMS configuration
PostgreSQL comes with a relatively low end configuration. This is intended to allow for it to run on a wide range of hardware (or VM) configurations. However, if you are running your Alfresco (and its database) on high end systems, you most certainly want to tune the configuration in order get the best out of your resources.
This wiki page present in details many parameters you may wan to tweak Tuning Your PostgreSQL Server - PostgreSQL wiki
The first one to look at is the shared_buffers size. It sets the size of the area PostgreSQL uses to cache data, thus improving performance. Among all those parameters some should be "in sync" with your Alfresco configuration. For example by default Alfresco allow 275 tomcat threads at peak time. Each of these threads should be able to open a database connection. As a consequence PostgreSQL (when installed using the installer) sets the max_connections parameter to 300. However we need to understand that each connection will consume resources, and in the first place: memory. The amount of memory dedicated to a PostgreSQL process (that handles a SQL query) is controlled by the work_mem parameter. By default it has a value of 4MB, meaning we can calculate the amount of physical RAM needed by the database server in order to handle peak load:
work_mem * max_connections = 4MB * 300 = 1.2GB
Add the size of the shared_buffers to this and you'll have a good estimate of the amount of RAM Postgres needs to handle peak loads with default configuration. There are some other important values to fiddle with (like effective_cache_size, checkpoint_completion_target, ...) but making sure those above are aligned with both your alfresco configuration and the hardware resources of your database host is really where to start (refer to the link above).
A qualified DBA should configure and maintain Alfresco's database to ensure continuous performance and stability of the database. If you don't have a DBA internally there are also dozens of companies offering good services around postgreSQL configuration and tuning.
Monitoring
This is a key in the troubleshooting process. Although monitoring will not give you solution to a performance issue it will help you getting on the right track. In this case having a monitoring in place on the DB server is important. If you can correlate an increasingly slow application with a global load increase on the database server, then you've got a good suspect. There are different things to monitor on the BD server but you should at least have the bare minimum:
- CPU
- RAM usage
- disk IO & disk space
Spikes in CPU and IO disk usage can be the sign of a table that grew large without appropriate indexes.
Spikes in the used disk space can be explained because of the RDBMS creating temporary work files due to a lack of physical memory.
Monitoring the RAM can help you anticipate cache disk memory starvation (PostgreSQL heavily rely on this kind of memory).
Alfresco has some tables that are known to be potentially growing very large. A DBA should monitor their size, both in terms of number of rows and disk size. The query bellow is an example of how you can do it:
SELECT table_name as tableName,
(total_bytes / 1024 / 1024) AS total,
row_estimate as rowEstimate,
(index_bytes / 1024 / 1024) AS INDEX,
(table_bytes / 1024 / 1024) AS TABLE
FROM (
SELECT *,
total_bytes-index_bytes-COALESCE(toast_bytes,0) AS table_bytes
FROM (
SELECT c.oid,
nspname AS table_schema,
relname AS TABLE_NAME,
c.reltuples AS row_estimate,
pg_total_relation_size(c.oid) AS total_bytes,
pg_indexes_size(c.oid) AS index_bytes,
pg_total_relation_size(reltoastrelid) AS toast_bytes
FROM pg_class c LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERErelkind = 'r') a) a
WHERE table_schema = 'public' order by total_bytes desc;
Usually the alf_prop_*, alf_audit_entry and possibly alf_node_properties are the tables that may appear in the resultset. There is no rule of thumb which dictate when a table is too large. This is more matter of monitoring how the table grow in time.
Another useful thing to monitor are the creation/usage of temporary files. When your DB is not correctly tuned, or doesn't have enough memory allocated to it, it may created temporary files on disk if it needs to further work on a big resultset. This is obvioulsy not as fast as working in-memory and should be avoided. If you don't know how to monitor that with your usual monitoring system there are some good tools that help a DBA be aware of such things hapenning.
pgbadger is an opensource tool which does that, and many other things. If you don't already use it, I strongly encourgae you to deploy it!
Debugging what takes long and how long is it?
Monitoring should have helped you pinpoint your DB server being over loaded, making your application slow. This could be because it is undersized for its workload (in which case you would probably see a steady high resource usage, or it could be some specific operations are too expensive for some reasons. in the former case, there is not much you can do apart from upgrading either the resources or the DB architecture (but that's not topics I want to cover here). In the later case, getting to know how long a query takes is really what people usually want to know. We accomplish that by using one of the debug option bellow.
At the PostgreSQL level
In my opinion, the best place to get this information is really on the DB server. That's where we get to know the actual execution time, without accounting for network round trip time and other delays. More over, PostgreSQL makes it very easy to enable this debug, and you don't even need to restart the server. There are many ways to enable debug in PostgreSQL, but the one that's the most interesting to us is log_min_duration_statement. By default it has a value of "-1" which means nothing will be logged based on its execution time. But for example, if we set in the postgresql.conf file:
log_min_duration_statement = 250
log_line_prefix = '%t [%p-%l] %q%u@%d '
Any query that takes more than 250 milliseconds to execute will be logged.
Setting the log_min_duration_statement value to zero will cause the system to log every single query. While this can be useful for debugging or for temporary audit this will not be very helpful here as we really want to target slow queries only.
If interested in profiling your DB have a look at the great pgbadger tool from Dalibo
The Alfresco installer sets by default thelog_min_messagesparameter tofatal. This prevent thelog_min_duration_statementfrom working. Make sure it is set back to its default value or to a value that's higher thanLOG.
Then without interrupting the service, PostgreSQL can be reloaded in order for changes to take effect:
$ pg_ctl -U postgres -W -D /data/postgres/9.4/main reload
adapt the command above to your needs with appropriate paths
This will produce an output such as bellow:
2017-12-12 19:54:55 CET [5305-1] LOG: duration: 323 ms execution : select
pv.id as prop_id,
pv.actual_type_id as prop_actual_type_id,
pv.persisted_type as prop_persisted_type,
pv.long_value as prop_long_value,
sv.string_value as prop_string_value
from
alf_prop_value pv
join alf_prop_string_value sv on (sv.id = pv.long_value and pv.persisted_type = $1)
where
pv.actual_type_id = $2 and
sv.string_end_lower = $3 and
sv.string_crc = $4
DETAIL: parameters: $1 = '3', $2 = '1', $3 = '4ed-f2f1d29e8ee7', $4 = '593150149'
Here we gather important informations:
- The date and time the query was executed at the beginning of the first line.
- The process ID and Session line number. As PostgreSQL forks a new process for each connection, we can map process ID and pool connections. A single connection may contain different transactions, which in turn will contain several statements. Each new statement processing increments the session line number
- The execution time on the first line
- The execution stage. A query is executed in several steps. With Alfresco making heavy usage of bind parameters, we will often see several lines for the same query (one for each step):
- prepare (when the query is parsed),
- bind (when parameters are replaced by their values and execution is planned),
- execution (when the query is actually executed).
- The query itself starting at the end of the first line and continuing on subsequent lines. Here it contains parameters and can't be executed as is.
- The bind parameters on the last line.
In order to get the overall execution time we have to sum up the execution time of the different steps. This seems painful but delivers fined grained breakdown of the query execution. However most of the time the majority of the execution time is spent on the execute stage, to better understand what's going on at this stage, we need to dive deeper into the RDBMS (see next chapter about explain plans).
At the application level
It is also possible to debug SQL queries in a very granular manner at the Alfresco level. However it is important to note that this method is way more intrusive as it required, adding additional jar files, modifying the configuration of the application and restarting the application server. It may not be well suited for production environments where any downtime is a problem.
Also note that execution times reported with this method include network round-trip times. In normal circumstances this should be few additionnal milliseconds, but could much more on a lame network.
To allow debugging at the application level we will use a jdbc proxy: p6spy
Impact on the application performances largely depends on the amount of queries that will be logged.
First of all we will get the latest p6spy jar file from the github repository.
Copy this file to the tomcat lib/ directory and add a spy.properties file in the same location containing the lines bellow:
driverlist:smileysurprised:rg.postgresql.Driver
executionThreshold=250
This will mimic the behaviour we had previously when debugging with PostgreSQL, meaning only queries that take more than 250 milliseconds will be logged.
We then need to tweak the alfresco-global.properties file in order to make it use the p6spy driver instead of the actual driver:
db.driver=com.p6spy.engine.spy.P6SpyDriver
db.url=jdbc:smileytongue:6spy:smileytongue:ostgresql://${db.host}/${db.name}Alfresco must now be restarted and we will have a new file called spy.log which should now be available and contain lines like the one shown bellow:
1513100550017|410|statement|connection 14|update alf_lock set version = version + 1, lock_token = ?, start_ti
me = ?, expiry_time = ? where excl_resource_id = ? and lock_token = ?|update alf_lock set
version = version + 1, lock_token = 'not-locked', start_time = 0, expiry_time = 0 where excl_resource_id
= 9 and lock_token = 'f7a21222-64f9-40ea-a00a-ef95052dafe9'We find here similar values to what we had with PostgreSQL:
- timestamp the query was executed on the application server.
- execution time in milliseconds
- The connection ID
- The query string without bind parameters
- The query string with evaluated bind parameters
Understanding the execution plan
Now that we have pinpointed the problematic query(ies) we can deep dive into PostgreSQL's logic and understand why the query is slow. RDBMS rely on their query planner to decide how to deal with a query.
The query planner itself makes decision based on the structure of the query, the structure of the database (e.g presence and types of indexes) and also based on statistics the system maintains during its execution. The more accurate those statistics are, the more efficient the query planer will be.
Explain plans
In order to know what the query planner would do for a specific query, it is possible to run it prefixed with the "EXPLAIN ANALYZE " statement.
To make this chapter more hands-on we'll proceed with an example. Let's consider a query which is issued while browsing the repository (get node informations based on parent). Using one of the methods we've seen above, we have identified that query an running it prefixed with "EXPLAIN ANALYZE" returns the following:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=6614.54..13906.94 rows=441 width=676) (actual time=1268.230..1728.432 rows=421 loops=1)
-> Hash Left Join (cost=6614.26..13770.40 rows=441 width=639) (actual time=1260.966..1714.577 rows=421 loops=1)
Hash Cond: (childnode.store_id = childstore.id)
-> Hash Right Join (cost=6599.76..13749.84 rows=441 width=303) (actual time=1251.427..1704.866 rows=421 loops=1)
Hash Cond: (prop1.node_id = childnode.id)
-> Bitmap Heap Scan on alf_node_properties prop1 (cost=2576.73..9277.09 rows=118749 width=71) (actual time=938.409..1595.742 rows=119062 loops=1)
Recheck Cond: (qname_id = 26)
Heap Blocks: exact=5205
-> Bitmap Index Scan on fk_alf_nprop_qn (cost=0.00..2547.04 rows=118749 width=0) (actual time=934.132..934.132 rows=119178 loops=1)
Index Cond: (qname_id = 26)
-> Hash (cost=4017.52..4017.52 rows=441 width=232) (actual time=90.488..90.488 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 83kB
-> Nested Loop (cost=0.83..4017.52 rows=441 width=232) (actual time=8.228..90.239 rows=421 loops=1)
-> Index Scan using idx_alf_cass_pri on alf_child_assoc assoc (cost=0.42..736.55 rows=442 width=8) (actual time=2.633..58.377 rows=421 loops=1)
Index Cond: (parent_node_id = 31890)
Filter: (type_qname_id = 33)
-> Index Scan using alf_node_pkey on alf_node childnode (cost=0.42..7.41 rows=1 width=232) (actual time=0.075..0.075 rows=1 loops=421)
Index Cond: (id = assoc.child_node_id)
Filter: (type_qname_id = ANY ('{142,24,51,200,204,206,81,213,97,103,231,104,107}'::bigint[]))
-> Hash (cost=12.00..12.00 rows=200 width=344) (actual time=9.523..9.523 rows=6 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on alf_store childstore (cost=0.00..12.00 rows=200 width=344) (actual time=9.517..9.518 rows=6 loops=1)
-> Index Scan using alf_transaction_pkey on alf_transaction childtxn (cost=0.28..0.30 rows=1 width=45) (actual time=0.032..0.032 rows=1 loops=421)
Index Cond: (id = childnode.transaction_id)
Planning time: 220.119 ms
Execution time: 1728.608 ms
Although I never faced it with PostgreSQL (more with Oracle), there are cases where the explain plans is different depending on whether you pass the query as a complete string or you use bind parameters.
In that case the parameterized query that may be found to be slow in the SQL debug logs might appear fast when executed manually.
To get the explain plan of these slow queries PostgreSQL has a loadable module which can log explain plans the same way we did with the log_duration. See the auto_explain documentation for more details.
We can indeed see that the query is taking rather long just by looking at the end of the output (highlighted in bold). However reading the full explain plan and more importantly understanding it can be challenging.
In the explain plan, PostgreSQL is breaking down the query into "nodes". Those "nodes" represent actions the RDBMS has to run through in order to execute the query. For example, at the bottom of the plan we will find the "scan nodes", which are the statements that actually return rows from tables. And upper in the plan we have "nodes" that correspond to aggregations or ordering. In the end we have an indented/hierarchical tree of the query from which we can detail each step. Each node (line starting with "-->") is shown with:
- its type, whether the system using indexes and what kind (Index scan) or not any (sequential scan)
- its estimated cost, an arbitrary representation of how costly an operation is.
- the estimated number of lines the operation would return
And much more details that make it somewhat hard to read.
And to make it more confusing, some values, like "cost" or "actual time", have two different values. To make it short you should only consider the second one.
The purpose of this article is not to learn how to fully understand a query plan, so instead,we will use a very handy online tool which ill parse the output for us and point out the problems we may have: New explain | explain.depesz.com
Only by pasting the same output and submitting the form we will get a better view of what's going on and what we need to look at.
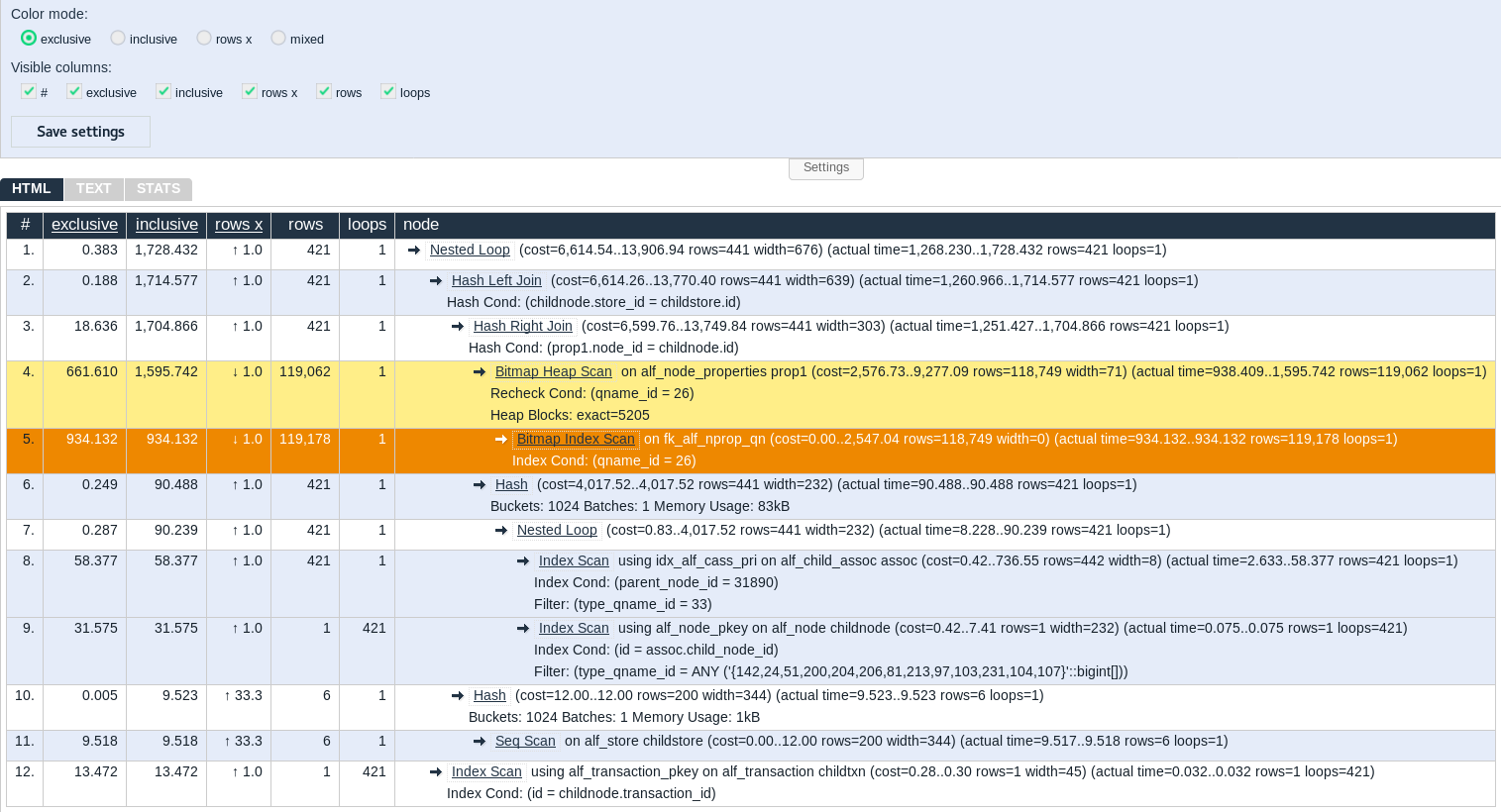
The "exclusive" color mode gives the best representation of how efficient each individual node is.
"Inclusive" mode is cumulative (so the top row will always be dark red as it's equal to the total execution time).
"rows x" shows how accurately the query planner is able to guess the number of rows.
If using "mixed" color mode, each cell in each mode's column will have its own color (which can be a little bit harder to read).
So here we can see straight away that nodes #4 & #5 are where we are spending most time. We can see that those nodes return a big amount of rows (more than 100 000 while there are only 421 of then in the final result set) meaning that the available indexes and statistics are not good enough.
Alfresco normally provide all the necessary indexes for the database to deliver good performance in most of the cases so it is very likely that queries under-performing because of indexes are actually missing indexes. Fortunately, Alfresco also deliver a convenient way to check the database schema for any in consistency.
Alfresco schema validation
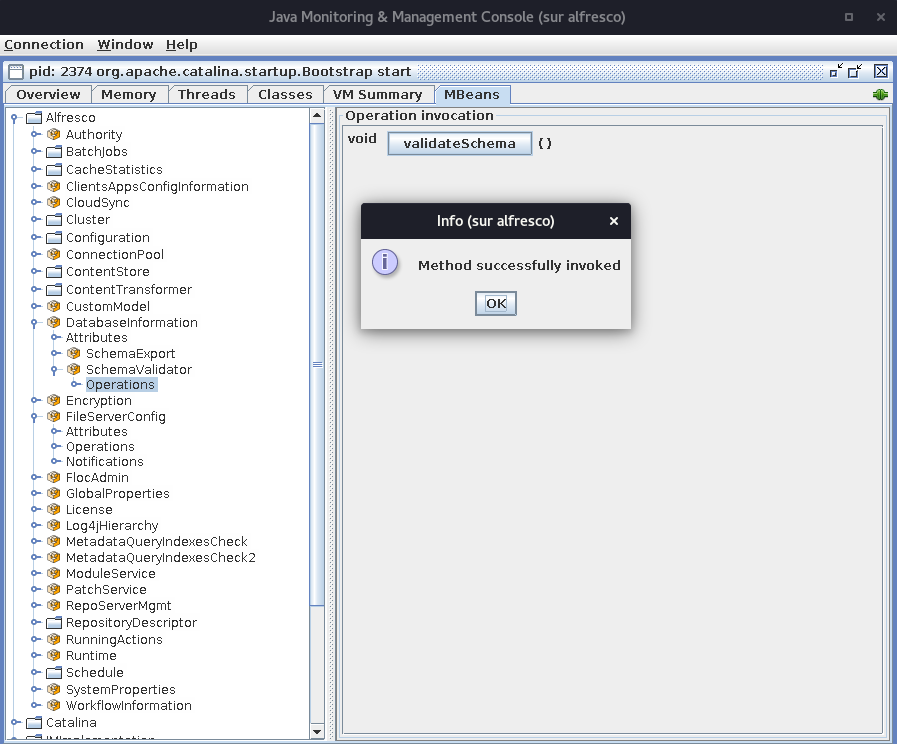
When connected to the JMX interface, in the MBeans tab, it is possible to trigger a schema validation while alfresco is running (go to "Alfresco \ DatabaseInformation \ SchemaValidator \ Operations" and launch "valideateSchema()").
This will produce the output bellow in the Alfresco log file:
2017-12-18 15:21:32,194 WARN [domain.schema.SchemaBootstrap] [RMI TCP Connection(6)-10.1.2.101] Schema validation found 1 potential problems, results written to: /opt/alfresco/bench/tomcat/temp/Alfresco/Alfresco-PostgreSQLDialect-Validation-alf_-4191170423343040157.txt
2017-12-18 15:21:32,645 INFO [domain.schema.SchemaBootstrap] [RMI TCP Connection(6)-10.1.2.101] Compared database schema with reference schema (all OK): class path resource [alfresco/dbscripts/create/org.hibernate.dialect.PostgreSQLDialect/Schema-Reference-ACT.xml]The log file points us to another file where we can see the details of the validation process. Here for example we can see that an index is indeed missing :
alfresco@alfresco:/opt/alfresco/bench$ cat /opt/alfresco/bench/tomcat/temp/Alfresco/Alfresco-PostgreSQLDialect-Validation-alf_-4191170423343040157.txt
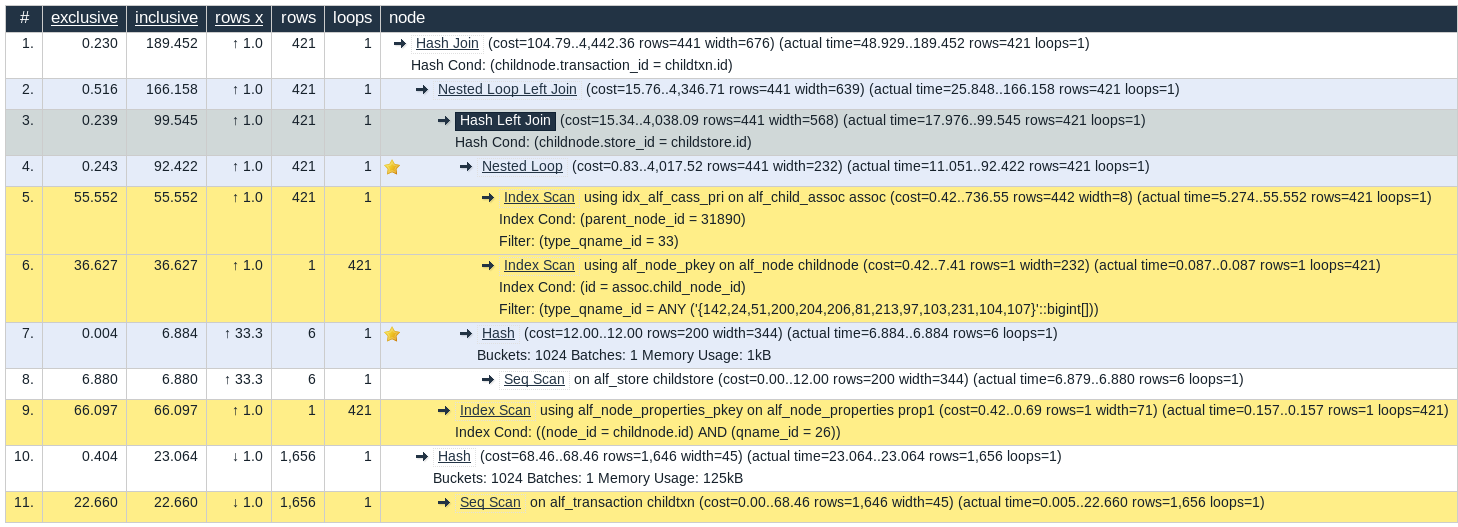
Difference: missing index from database, expected at path: .alf_node_properties.alf_node_properties_pkeyThe index can now be re-created either taking a fresh install as a model or by getting in touch with alfresco support to know how to create the index.
The resulting - more efficient - query plan if much better:
Database statistics
Statistics are really critical to PostgreSQL performance as it's what mainly offer the query planner efficiency. With accurate statistics PostgreSQL will make good decision when planning a query. And of course, inaccurate statistics leads to bad decisions and so bad performances.
PostgreSQL has an internal process in charge of keeping statistics up to date (in addition to other house keeping tasks): the autovacuum process.
All versions of PostgreSQL Alfresco supports have this capability and it should always be active! By default this process will try to update statistics according to configuration options set in postgresql.conf. The options bellow can be useful to fine tune the autovacuum behaviour (those are the defaults):
autovacuum=true #Enable the autovacuum daemon
autovacuum_analyze_threshold=50 #Number of tuples modifications that trigger ANALYZE
autovacuum_analyze_scale_factor = 0.1 #Fraction of table modified to trigger ANALYZE
default_statistics_target = 100 # Amount of information to store in the statistics
autovacuum_analyze_threshold&autovacuum_analyze_scale_factormust be summed up in order to know when an ANALYZE will be triggered
If you saw a slow, but constant degradation in queries performances it maybe that some tables grew large enough to make the default parameters not as efficient as they used to be. As the tables grow, the scale factor can make statistics update very infrequent, lowering autovacuum_analyze_scale_factor will make statistics updates more frequent, thus ensuring stats are more up to date.
The type of data distribution within a database tables can also change during its lifetime, either because of a data model change of simply because of new use-cases. Raising default_statistics_target will make the daemon collect and process more data from the tables when generating or updating statistics, thus making the statistics more accurate.
Of course asking for more frequent dates and more accurate statistics as an impact on the resources needed by the autovacuum process. Such tweaking should be carefully done by your DBA.
Also it is important to note that the options above are applied for every table. You may want to do something more targeted to known big tables. This is doable by changing the storage options for the specific tables:
=# ALTER TABLE alf_node_prop_string_value
-# ALTER COLUMN string_value SET STATISTICS 1000;
Above SQL statement is really just an example and must not be used without prior investigations
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Related Content
- Alfresco 6.0 hangs intermittently on Windows VM – uploads/downloads stop, no clear error in logs in Alfresco Forum
- Bring Alfresco Search to 2026: Vanilla Solr 9, Java 17, and an invitation to the Community (by Jeci) in Alfresco Blog
- Building Permission-Aware Semantic Search on Alfresco with hxpr and Content Lake in Alfresco Blog
- Restored PostgreSQL .sql Backup – Database Tables Exist but Alfresco Share Shows No Data in Alfresco Forum
- Alfresco Community Edition 23.4 Release Notes in Alfresco Blog
