Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Hyland Connect
- Platform
- Alfresco
- Alfresco Forum
- Re: UnsupportedTranformationException
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
UnsupportedTranformationException
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2017 02:21 PM
Hi,
I have an issue with the transformation from PDF to HTML.
Here is the Rule:
 https://i.imgur.com/4uFsKZr.png
https://i.imgur.com/4uFsKZr.png
"Caused by: org.alfresco.repo.content.transform.UnsupportedTransformationException: 00270053 Transformation of (pdfdocname.html) has not taken place because the
declared mimetype (text/html) does not match the detected mimetype (application/xhtml+xml)."
Somehow the detected mimetype is always "xhtml+xml" instread of PDF.
The document is displayed just fine. I tried various PDFs.

In the "Transformed" directory I simply have:

Server Logs:
Caused by: org.alfresco.service.cmr.rendition.RenditionServiceException: 00270033 Some error occurred during document transforming. Error message: 00270031 Transform
ation of (bestmeat_best_v=1 (1).html) has not taken place because the declared mimetype (text/html) does not match the detected mimetype (application/xhtml+xml).
at org.alfresco.repo.rendition.executer.AbstractTransformationRenderingEngine$TransformationCallable$1.doWork(AbstractTransformationRenderingEngine.java:456)
at org.alfresco.repo.rendition.executer.AbstractTransformationRenderingEngine$TransformationCallable$1.doWork(AbstractTransformationRenderingEngine.java:1)
at org.alfresco.repo.security.authentication.AuthenticationUtil.runAs(AuthenticationUtil.java:555)
at org.alfresco.repo.rendition.executer.AbstractTransformationRenderingEngine$TransformationCallable.call(AbstractTransformationRenderingEngine.java:437)
at org.alfresco.repo.rendition.executer.AbstractTransformationRenderingEngine$TransformationCallable.call(AbstractTransformationRenderingEngine.java:1)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
... 3 more
Caused by: org.alfresco.repo.content.transform.UnsupportedTransformationException: 00270031 Transformation of (bestmeat_best_v=1 (1).html) has not taken place becaus
e the declared mimetype (text/html) does not match the detected mimetype (application/xhtml+xml).
at org.alfresco.repo.content.transform.AbstractContentTransformer2.strictMimetypeCheck(AbstractContentTransformer2.java:457)
at org.alfresco.repo.content.transform.AbstractContentTransformer2.transform(AbstractContentTransformer2.java:255)
at org.alfresco.repo.content.ContentServiceImpl.failoverTransformers(ContentServiceImpl.java:668)
at org.alfresco.repo.content.ContentServiceImpl.transform(ContentServiceImpl.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:317)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:183)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at net.sf.acegisecurity.intercept.method.aopalliance.MethodSecurityInterceptor.invoke(MethodSecurityInterceptor.java:80)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.alfresco.repo.model.ml.MLContentInterceptor.invoke(MLContentInterceptor.java:136)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.alfresco.repo.security.permissions.impl.ExceptionTranslatorMethodInterceptor.invoke(ExceptionTranslatorMethodInterceptor.java:53)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.alfresco.repo.audit.AuditMethodInterceptor.invoke(AuditMethodInterceptor.java:166)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:96)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:260)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:94)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:204)
at com.sun.proxy.$Proxy54.transform(Unknown Source)
at org.alfresco.repo.rendition.executer.AbstractTransformationRenderingEngine$TransformationCallable$1.doWork(AbstractTransformationRenderingEngine.java:447)
... 8 more
Labels:
- Labels:
-
Alfresco Content Services
8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-28-2017 08:59 AM
I really am not sure that this message relates directly to the rule you have included in the screenshot. In the error message it complains about a transformation that is supposed to be from some HTML file to some target, where the source file is defined as text/html while Alfresco / TIKA detects it as being application/xhtml+xml. Unfortunately due to the various versions of (X)HTML, file naming and sloppy content structures, HTML files can easily be misclassified as XHTML and vice versa.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2017 06:21 AM
UPDATE: I just figured that some PDFs are correctly converted BUT cannot be displayed most likely due to the wrong mimetype detection:
$ file 2026140_v\=1.html
2026140_v=1.html: HTML document text, UTF-8 Unicode text
This file actually contains readable PDF text. However, if I do a OCRd version conversion the HTML output is 1K, aka zero.
This implies another problem.
Hi Axel,
this error message appears once I click on the generated HTML file from the PDF in the "Transformed" folder. However, I have no transformation rule in that folder to further convert the HTML hence this is what should have already happened before. So the HTML is only 1K of size. I even tried to disable the transformation check with
transformer.strict.mimetype.check=false
which didn't help either. This is what appears when trying to load along with the error message above:
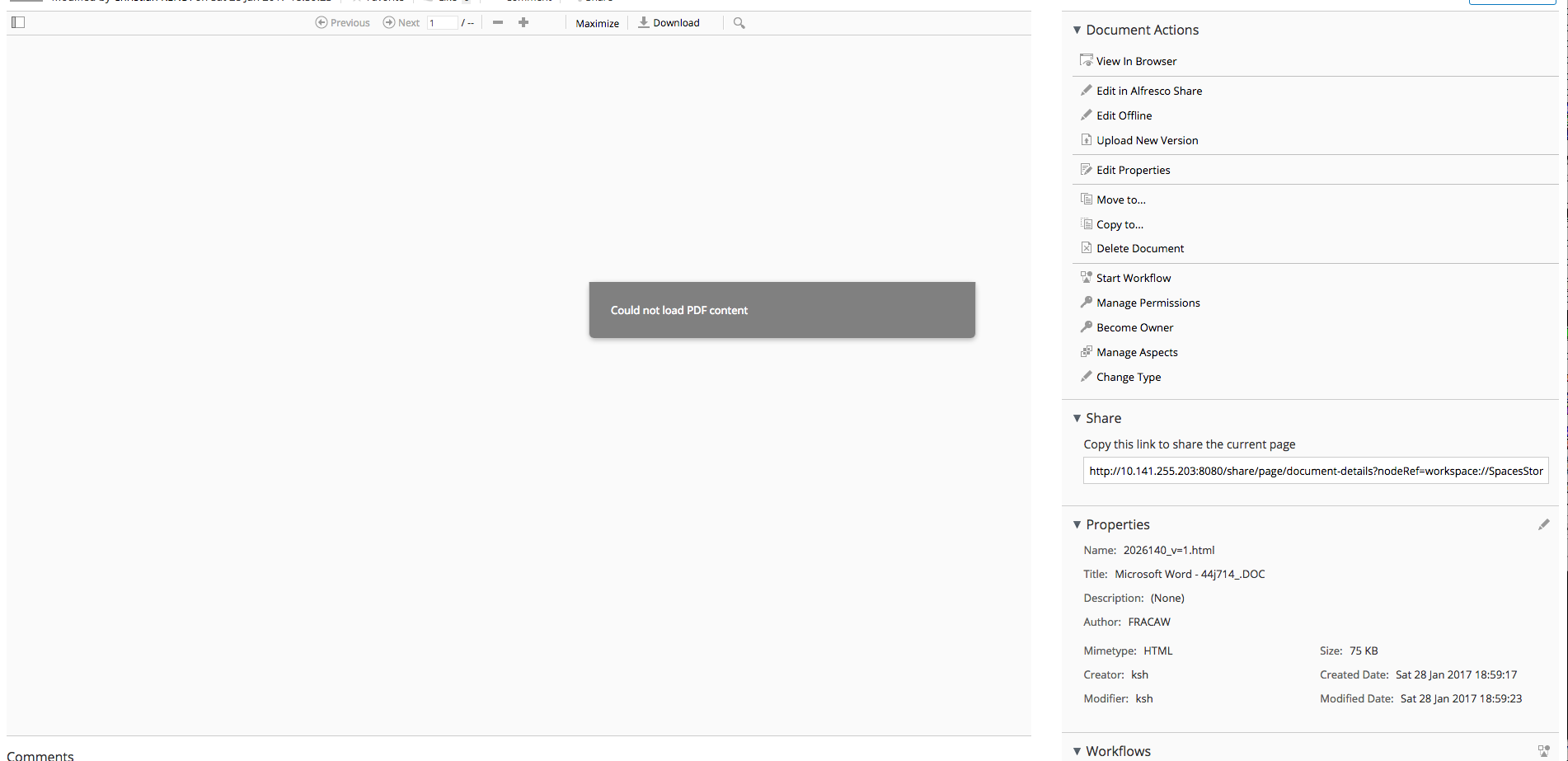
Is there a chance that the generated HTML from the PDF transforms into a (X)HTML und thus is misclassified?
Furthermore, editing doesn't show any text either.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2017 09:43 AM
I would not classify 1K as zero.
But it looks like the conversion of PDF to HTML results in a XHTML classified file that only has the HTML mimetype associated with it. The mimetype handling that treats HTML different from XHTML might be a bit pedantic here, since most people likely aren't even aware of the differences and would throw these types into the same basket.
Disabling the strict mimetype check should have worked - there is a very direct check of this setting in the codebase.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2017 10:57 AM
So i've been digging and found this:
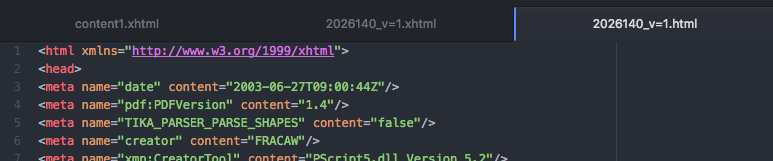
XHTML produces at its head:
<?xml version="1.0" encoding="UTF-8"?><html xmlns="http://www.w3.org/1999/xhtml">
It seems that the mimetype check is broken as well.
$ file 2026140_v\=1.*
2026140_v=1.html: HTML document text, UTF-8 Unicode text
2026140_v=1.xhtml: XML 1.0 document text, UTF-8 Unicode text
Nevertheless, this is implies an old error that XHTML cannot be previewed, which I found here:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2017 05:23 PM
Yeah - this was part of the issue in ALF-18696 but as far as I can see from the comments they just fixed the issue that affected the wiki display of XHTML, and not the transformation of XHTML to a previewable PDF document. So that part of ALF-18696 is still very much an "unresolved issue".
The mimetype check in Alfresco is slightly more elaborate than what the command line "file" utility does. It will actually check the content and not the file name. The check for XHTML files does multiple different checks, one is to check for a "xmlns" attribute on the "html" tag. In the case of your file it is present in the "2026140_v=1.html" so the mimetype check treats it as XHTML, while the original mimetype (in the content URL) was determined by the PDF-to-HTML conversion. That conversion should actually set XHTML as the mimetype (and extension) so that there is no mismatch. That would then only leave the only remaining issue: lack of XHTML preview support in Alfresco.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-29-2017 07:39 PM
I partially agree up to the point that I wanted PDF-to-HTML conversion and not PDF-to-XHTML. XHTML would be fine but for further processing XHTML to DOC is not supported. Should this be filed as a bug?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2017 01:49 AM
It could be considered a bug for the PDF to HTML transformer that it produces XHMTL instead, correct. Unfortunately I don't know which converter is responsible for that (no one usually ever does this type of conversion). If you have the OOTBee Support Tools addon installed, you can use its Admin Console tool for transformations to find out which transformer is being used.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-30-2017 05:43 AM
ok. let me check if I find the amp file for the OOTBee tools. Thx!
Getting started
Explore our Alfresco products with the links below. Use labels to filter content by product module.
