Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Hyland Connect
- Platform
- Alfresco
- Alfresco Forum
- Re: Expand query result in Node Browser
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Expand query result in Node Browser
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-12-2018 05:22 AM
Hi guys,
How to expand the query result in the node browser? it says showing first 100 only? can anyone help me on this? And on the select query, what values will be use for the IN_TREE parameter? '
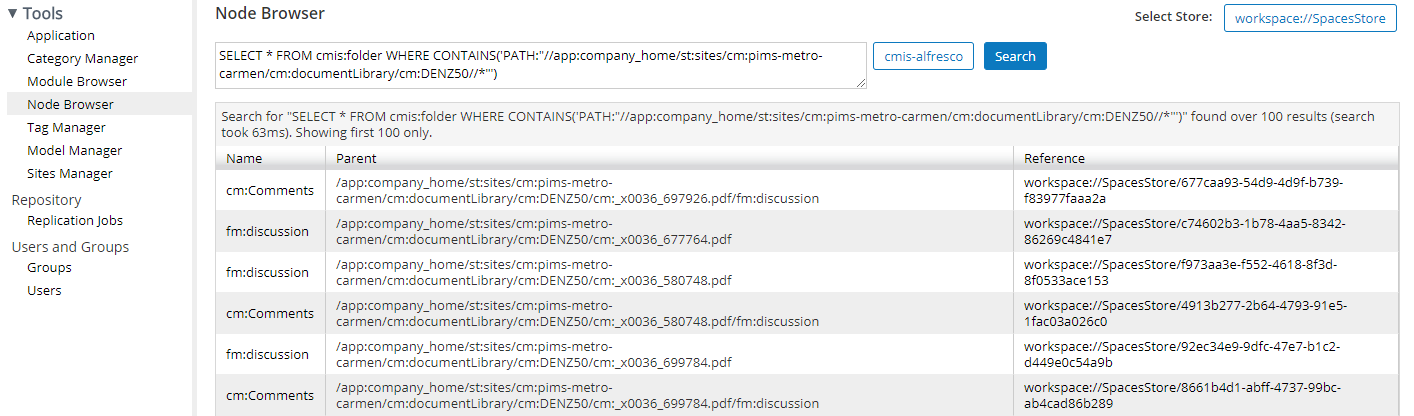
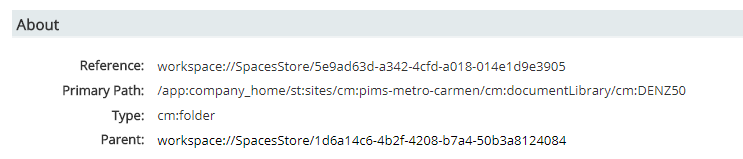
Example: SELECT * FROM cmis:document WHERE IN_TREE('5e9ad63d-a342-4cfd-a018-014e1d9e3905'). Will I choose any of these workspace to get to the right folder? which one? parent or reference? (Please see photo below) and
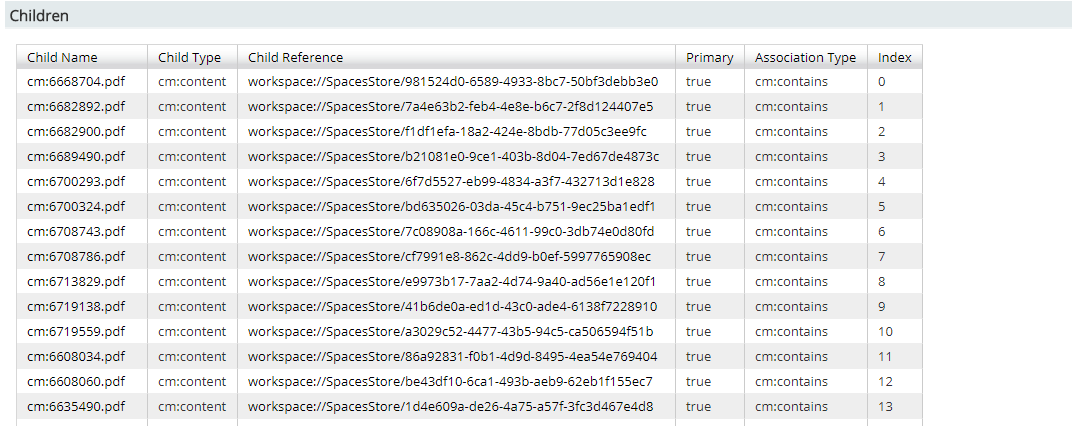
I just want only to display thse pdf file items only. Can someone help me on this? (Please see photo below)
P.S
Im new here and Im confused on this node browser query. Sorry for the inconvenience.
Thanks 
Labels:
- Labels:
-
Alfresco Content Services
8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-12-2018 08:12 AM
See my response in your original question regarding the IN_TREE selector.
There is no way to expand the number of results in the node browser beyond the 100 items limitation. The purpose of the tool is to test queries and use queries to find a limited number of results from an administrator's perspective, i.e. to check the state of a specific node. As such you should probably refine your query to restrict the number of results a bit further.
Otherwise I would advise you to use the JavaScript Console addon to do any kind of more elaborate query + analysis operations.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-12-2018 09:16 PM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-13-2018 10:13 AM
What do you mean by "extract"? Do you want to download, archive or process them, or something else entirely? Or are you talking about the JavaScript Console addon and how to install it?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-15-2018 08:34 PM
Yes, we want to download, archive those items. is there a possible way to do it?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-16-2018 03:46 AM
Not from the NodeBrowser itself. But if you were to scrape the results from that page and use a ReST API call to the downloads.post web script (/alfresco/s/api/internal/downloads) you could easily create a download archive. Alternatively, you could use the JavaScript Console to execute the same query via the root scope "search" object, create a temporary folder where you link all the results as children and then use the "export" action to export that folder as an ACP (Alfresco Content Package), which is a ZIP file containing metadata and content in a way that can be imported into another Alfresco system.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-16-2018 03:57 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-16-2018 04:03 AM
Apparently...
There is work needed to create new API. All you have to do is work with the existing API to achieve your goals / requirements. And I listed two approaches to work with the existing API to do what you have mentioned. Either use the internal ReST API (used primarily for the Share user interface) to have Alfresco create a ZIP archive as a new document / node which you can then download, or use the JavaScript API access to search, nodes and actions to create an ACP archive (again, as a new document / node which you can then download).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-16-2018 04:07 AM
Related Content
- Building Permission-Aware Semantic Search on Alfresco with hxpr and Content Lake in Alfresco Blog
- A practical walkthrough of the Alfresco Model Context Protocol in Alfresco Blog
- REST API returns unauthorized for preview request (renditions) when SSO is enabled in Community 7.3 in Alfresco Forum
- Problem with APS in the same docker compose with ACS in Alfresco Forum
- different search result from [Alfresco share] and using REST API Search/Solr6 in Alfresco Forum
Getting started
Explore our Alfresco products with the links below. Use labels to filter content by product module.
