Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Hyland Connect
- Platform
- Alfresco
- Alfresco Blog
- Refreshing UAT environment: pitfalls to avoid
alxgomz

Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-12-2017
07:05 AM
If you are serious about Alfresco in your IT infrastructure you most certainly have a "User Acceptance Tests" environment. If you don't... you really should consider setting one up (don't make Common mistakes)!
When you initially set up your environments everything is quiet, users are not using the system yet and you just don't care about data freshness. However, soon after you go live, the production system will start being fed with data. Basically it is this data, stored in Alfresco Content Service, that make your system or application valuable.
When the moment comes to upgrade or deploy a new customization/application, you will obviously test it first on your UAT (or pre-production or test, whatever you call it) environment. Yes you will!
When you do so, having a UAT environment that doesn't have an up-to-date set of data can make the tests pointless or more difficult to interpret. This is also true if you plan to do kick off performance tests. If the tests are done on a data set that is only one third the size of the production data, it's pointless.
Basically that's why you need to refresh your UAT data with production data every now and then or at least when you know it's going to be needed.
The scope of this document is not to provide you with a step by step guide on how to refresh your repository. Alfresco Content Services being a platform, this highly depends on what you actually do with your repository, the kind of customization you are using and 3rd parties apps that could be link to Alfresco anyhow. This document will mainly highlight things you should thoroughly check when refreshing your dataset.
Prerequisites
Some thing must be validated before going further:
- Production & UAT environments should have the same architecture (same number of servers, same components installed, and so on and so forth...)
- Production & UAT environments should have the same sizing (while you can forget this for functional tests only, this is a true requirement for performance tests of course)
- Production & UAT environments should be hosted on different, clearly separated networks (mostly if using cluster)
What is it about?
In order to refresh your UAT repository with data from production you will simply go through the normal restore process of an Alfresco repository.
Here I consider backup strategy is not a topic... If you don't have proper backups already set up, that's where you should start: Performing a hot backup | Alfresco Documentation
The required assets to restore are:
- Alfresco's database
- Filesystem repository
- Indexes
Before you start your fresh UAT
There a re a number of things you should check before starting your refreshed environment.
Reconfigure cluster
Although the recommendation is to isolate environments it is better to specify different cluster configuration for both environments. That will allow for a less confusing administration and log analysis and also prevent information leaking from one network to another in case isolation is not that good.
When starting a refreshed UAT cluster, you should always make sure you are setting a cluster password or a cluster name that is different from production cluster. Doing so you prevent yourself from cluster communication to happen between nodes that are actually not part of the same cluster:
alfresco.hazelcast.password=someotherpassword
Alfresco 4.2 onward
alfresco.cluster.name=uatCluster
Alfresco pre-4.2
On the Share side, it is possible to change more parameters in order to isolate clusters but we will still apply the same logic for the sake of simplicity. Here you would change the Hazelcast password in the custom-slingshot-application-context.xml configuration file inside the {web-extension} directory.
<hz:topic id="topic" instance-ref="webframework.cluster.slingshot" name="slingshot-topic"/>
<hz:hazelcast id="webframework.cluster.slingshot">
<hz:config>
<hz:group name="slingshot" password="notthesamepsecret"/>
<hz:network port="5801" port-auto-increment="true">
<hz:join>
<hz:multicast enabled="true" multicast-group="224.2.2.5" multicast-port="54327"/>
<hz:tcp-ip enabled="false">
<hz:members></hz:members>
</hz:tcp-ip>
</hz:join>
...
Email notifications
It's very unlikely that your UAT environment needs to send emails or notifications to real users. Your production system is already sending digest and other emails to users and you don't want them to get confused because they received similar emails from other systems. So you have to make sure emails are either:
- Sent to a black hole destination
- Sent to some other place where users can't see them
If you really don't care about emails generated by Alfresco, then you can choose the "black hole" option. There are many different ways to do that, among which configuring your local MTA to send all emails to a single local user and optionally link his mailbox to /dev/null (with postfix you could use canonical_maps directive and mbox storage). Another way to do that would be to use the java DevNull SMTP server. It is very simple to use as it is just a jar file you can launch
java -jar -console -p 10025 DevNull.jar
On the other hand, as part of your users tests, you may be interested in knowing and analyzing what emails generated by your Alfresco instance. In this case you could still use previous options. Both are indeed able to store emails instead of swallowing them, postfix by not linking the mbox storage to /dev/null, and DevNull SMTP server by using the "-s /some/path/" option. However storing emails on the filesystem is not really handy if you want to check their content and the way it renders (for instance).
If emails is a matter of interest then you can use other products like mailhog or mailtrap.io. Both offer an SMTP server that stores emails for you instead of sending it to the outside world, but they also offer a neat way to visualize them, just like a webmail would do.
Mailtrap.io is a service that also offer advanced features like POP3 (so you can see emails in "real-life" clients), SPAM score testing, content analysis and for subscription based users, collaboration features.
Whatever option is yours, and based on the chosen configuration you'll have to switch the following properties for you UAT Alfresco nodes:
mail.host
mail.port
mail.smtp.auth
mail.smtps.auth
mail.username
mail.password
mail.smtp.starttls.enable
mail.protocol
Jobs & FSTR synchronisation
Alfresco allows an administrator to schedule jobs and setup replication to another remote repository.
Scheduled jobs are carried over from production environments to UAT if you cloned environments or proceeded to a backup/restore of production data. However you most certainly don't want the same job to run twice from two different environments.
Defining whether or not a job should run in UAT depends on a lot of factor and is very much related to what the job actually does. Here we cannot give a list of precise actions to take in order to avoid problem. It is the administrator's call to review Scheduled jobs and decide whether or not he should/can disable them.
Jobs to review can be found a in spring bean definitions file like ${extensionRoot}/extension/my-scheduler-context.xml.
One easy way to disable jobs can be to set a cron expression to a far future (or past)
<property name="cronExpression">
<value>0 50 0 * * 1970</value>
</property>
The repository can also hold synchronization jobs. Mainly those jobs that are used in File Transfer Receiver setups.
In that case the administrator surely have to disable such jobs (or at least reconfigure them) as you do not want UAT frozen data to be synced to a remote location where live production data is expected!
Disabling this kind of jobs is pretty simple. You can do it using the Share web UI by going to the "Repository \ Data Dictionary \ Transfers \ Default Target group \ Group1" and edit properties of the "Group1" folder. In the property editor form, just untick the "Activated" checkbox.
Repository ID & Cloud synchronization
Alfresco repository IDs must be universally unique. And of course if you clone environments, you create duplicated repository IDs. One of the well known issue that can be triggered by duplicate IDs is for hybrid cloud setups where synchronization is enabled between the production environment and the Cloud my.alfresco.com. If your UAT servers connect to the cloud with the production's ID you can be sure synchronization will fail at some point and could even trigger data loss on your production system. You really want to avoid that from happening!
One very easy way to prevent this from happening is to simply disable clouds sync on the UAT environment.
system.serverMode=UAT
Any string other than "PRODUCTION" can be used here. Also be aware that this property can only be set in alfresco-global.properties file
Also if you are using APIs that need to specify the repository ID in order to request Alfresco (like old CMIS endpoint used to) then such API calls may stop working in UAT as the repo ID is now the one from production (in the case the calls where initially written with a previous ID, and it is not gathered previously - which would be a poor approach in most cases).
Starting with Alfresco 4.2, CMIS now returns the string "-default-" as a repository ID, for all new API endpoints (e.g. atompub /alfresco/api/-default-/public/cmis/versions/1.1/atom), while previous endpoint (e.g. atompub /alfresco/cmisatom) returns a Universally Unique IDentifier.
If you think you need to change the repository ID, please contact Alfresco support. It makes the procedure heavier (a re-index is expected) and should be thoroughly planned.
Carrying unwanted configuration
If you stick to the best practices for production, you probably try to have all your configuration in properties or xml files in the {extensionRoot} directory.
But on the other hand, you may sometimes use the great facilities offered by Alfresco enterprise, such you as JMX interface or the admin console. You must then remember those tools will persist configuration information to the database. This means that, when restoring a database from one environment to another one, you may end up starting an Alfresco instance with wrong parameters.
Here is a quite handy SQL query you can use *before* starting your new Alfresco UAT. It will report all the properties that are stored in the database. You can then make sure none of them is harmful or points to a production system.
SELECT APSVk.string_value AS property, APSVv.string_value AS value
FROM alf_prop_link APL
JOIN alf_prop_value APVv ON APL.value_prop_id=APVv.id
JOIN alf_prop_value APVk ON APL.key_prop_id=APVk.id
JOIN alf_prop_string_value APSVk ON APVk.long_value=APSVk.id
JOIN alf_prop_string_value APSVv ON APVv.long_value=APSVv.id
WHERE APL.key_prop_id <> APL.value_prop_id
AND APL.root_prop_id IN (SELECT prop1_id FROM alf_prop_unique_ctx);
property | value
------------------------------------------+--------------------------------------
alfresco.port | 8084
Do not try to delete those entries from the database straight away this is likely to brake things!
If any property is conflicting with the new environment, it should be removed.
Do it wisely! An administrator should ALWAYS prefer using the "Revert" operations available through the JMX interface!
The "revert()" method is available using jconsole, in the Mbean tab, within the appropriate section:
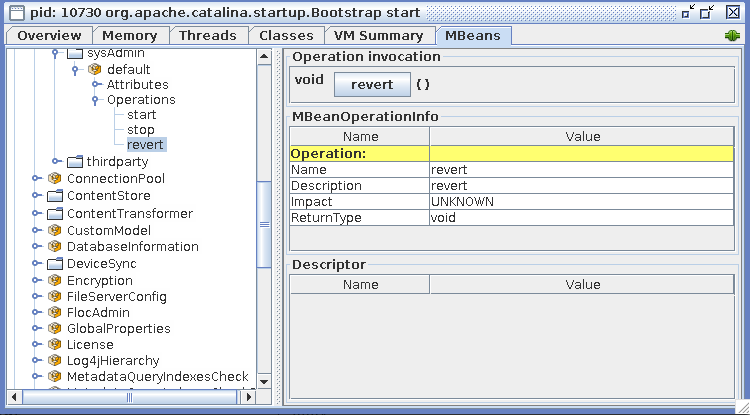
"revert()" may revert more properties than just the one you target. If unsure how to get rid of a single property, please contact alfresco support.
Other typical properties to change:
When moving from environment the properties bellow are likely to be different in UAT environment (that may not be the case for you or you may have others). As said earlier they should be set in the ${extensionroot} folder to a value that is specific to UAT (and they should not be present in database):
ldap.authentication.java.naming.provider.url
ldap.synchronization.java.naming.security.principal
ldap.synchronization.java.naming.security.credentials
solr.host
solr.port
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Related Content
- A practical walkthrough of the Alfresco Model Context Protocol in Alfresco Blog
- The Alfresco Community went to FOSDEM 2026 and all I got was this blog post in Alfresco Blog
- Can I run Alfresco community 201707 GA on a more current Tomcat like 8.0/8.5/9? The release notes only speak of Tomcat 7. Thank you! in Alfresco Forum
- Activiti 7 Deep Dive Series - Using the Core Libraries in Alfresco Blog
- Activiti 7 Deep Dive Series - Building, Deploying, and Running a Custom Business Process in Alfresco Blog
