Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Hyland Connect
- Platform
- Alfresco
- Alfresco Blog
- Document Fingerprints
andy1

Star Collaborator
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-12-2017
07:55 AM
Introduction
Support to find related documents by content fingerprint, given a source document, was added in Alfresco Content Services 5.2 and is exposed as part of the Alfresco Full Text Search Query Language. Document fingerprints can be used to find similar content in general or biased towards containment. The language adds a new FINGERPRINT keyword:
FINGERPRINT:<DBID | NODEREF | UUID>
By default, this will find documents that have any overlap with the source document. The UUID option is likely to be the most common as UUID is ubiquitous in the public API. To specify a minimum amount of overlap use
FINGERPRINT:<DBID | NODEREF | UUID>_<%overlap>
FINGERPRINT:<DBID | NODEREF | UUID>_<%overlap>_<%probability>
FINGERPRINT:1234_20
Will find documents that have 20% overlap with the document 1234.
FINGERPRINT:1234_20_80
Will execute a faster query that will be 80% confident anything brought back will overlap by 20%
Additional information is added to the SOLR 4 or 6 indexes using the rerank template to support fingerprint queries. It makes the indexes ~15% bigger.
The basis of the approach taken here and a much wider discussion is presented in Mining of Massive Datasets, Chapter 3. Support to generate text fingerprints was contributed by Alfresco to Apache Lucene via LUCENE-6968. The issue includes some more related material.
Similarity and Containment
Document similarity covers duplicate detection, near duplicate detection, finding different renditions of the same content, etc. This is important to find and reduce redundant information. Fingerprints can provide a distance measure to other documents, often based on Jaccard distance, to support "more like this" and clustering. The distance can also be used as a basis for graph traversal. Jaccard distance is defined as:
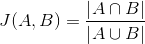
the ratio of the amount of common content to the total content of two documents. This distance can be used to compare the similarity of any two documents with any other pair of documents.
Containment is related but is more about inclusion. For example, many email threads include parts or all of previous messages. Containment is not symmetrical like the measure of similarity above, and is defined as:
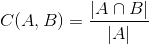
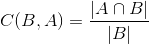
It represents how much of the content of a given document is common to another document. This distance can be used to compare a single document (A) to any other document. This is the main use case we are going to consider.
Minhashing
Minhashing is an example of a text processing pipeline. First, the text is split into a stream of words; these words are then combined into five word sequences, known as shingles, to produce a stream of shingles. So far, all standard stuff available in SOLR. The 5-word shingles are then hashed, for example, in 512 different ways; keeping the lowest hash value for each hash. This results in 512 repeatably random samples of 5 word sequences from the text represented by the hash of the shingle. The same text will generate the same set of 512 minhashes. Similar text will generate many of the same hashes. It turns out that if 10% of all the min hashes from two documents overlap then it is a great estimator that J(A,B) = 0.1.
Why 5 word sequences? A good question. Recently, word embedding suggests 5 or more words are enough to describe the context and meaning of a central word. Looking at the distribution of words, 2 word shingles, 3 word shingles, 4 word shingles and 5 word shingles found on the web; at 5 word shingles the frequency distribution flattens and broadens compared with the trend seen for 1, 2, 3 and 4 word shingles.
Why 512 hashes? With a well distributed hash function this should give good hash coverage for 2,500 words and around 10% for 25,000, or something like 100 pages of text.
We used a 128-bit hash to encode both the hash set position (see later) and hash value to minimise collision compared with a 64 bit encoding including bucket/set position.
An example
Here are 2 summaries of the 1.0 and 1.1 CMIS specification. It demonstrates, amongst other things, how sensitive the measure is to small changes. Adding a single word affects 5 shingles.

The content overlap of the full 1.0 CMIS specification found in the 1.1 CMIS specification, C(1.0, 1.1) ~52%.
The MinHashFilter in Lucene
The MinHashFilterFactory has four options:
- hashCount - the number of real hash functions computed for each input token (default: 1)
- bucketCount - the number of buckets each hash is split into (default: 512)
- hashSetSize - for each bucket, the size of the minimum set (default:1)
- withRotation - empty buckets take values from the next with wrap-around (default: true if bucketCount > 1 )
Computing the hash is expensive. It is cheaper to split a single hash into sub-ranges and treat each as supplying an independent minhash. Using individual hash functions, each will have a min value - even if it is a duplicate. Splitting the hash into ranges means this duplication can be controlled using the withRotation option. If this option is true you will always get 512 hashes - even for very short docs. Without rotation, there may be less than 512 hashes depending on the text length. You can get similar, but biased, sampling using a minimum set of 512.
Supporting a min set is in there for fun: it was used in early minhash work. It leads to a biased estimate but may have some interesting features. I have not seen anyone consider what the best combination of options may be. The defaults are my personal opinion from reading the literature linked on LUCENE-6968. There is no support for rehashing based on a single hash as I believe the bucket option is more flexible.
Here are some snippets from our schema.xml:
....
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUNormalizer2FilterFactory" name="nfkc_cf" mode="compose" />
<filter class="solr.ShingleFilterFactory" minShingleSize="5" maxShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" tokenSeparator=" " />
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" hashCount="1" hashSetSize="1" bucketCount="512" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
</fieldType>
.....
<field name="MINHASH" type="identifier" indexed="true" omitNorms="true" stored="false" multiValued="true" required="false" docValues="false"/>
.....
<field name="min_hash" type="text_min_hash" indexed="true" omitNorms="true" omitPositions="true" stored="false" multiValued="true" />
It is slightly misleading as we use the min_hash field as a way of finding an analyser to use internally to fill the MINHASH field. We also have a method to get the MINHASH field values without storing them in the index. Others would most likely have to store it in the index.
Query Time
At query time, the first step is to get hold of the MINHASH tokens for the source document - we have a custom search component to do that in a sharded environment form information we persist along side the index. Next you need to build a query. The easy way is to just OR together queries for each hash in a big boolean query. Remember to use setDisableCoord(true) to get the right measure of Javccard distance.. Applying a cut-off simply requires you to setMinimumNumberShouldMatch() based on the number of hashes you found.
Building a banded query is more complicated and derived from locality sensitive hashing, described in Mining of Massive Datasets, Chapter 3. Compute the band size as they suggest, based on the similarity and expected true positive rate required. For each band, build a boolean query that must match all the hashes in a band selected from the source docs fingerprint. Then, OR all of these band queries together. Avoid the trap of making a small band at the end by wrapping around to the start. This gives better query speed at the expense of accuracy.
Labels:
7 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Related Content
- First Look: OpenSearch Support in Alfresco Community 26.2 (Preview) in Alfresco Blog
- Bring AI agents to Alfresco safely with the new Docker Sandboxes kit in Alfresco Blog
- Bring Alfresco Search to 2026: Vanilla Solr 9, Java 17, and an invitation to the Community (by Jeci) in Alfresco Blog
- Building Permission-Aware Semantic Search on Alfresco with hxpr and Content Lake in Alfresco Blog
- 15 Extra Transform Engines for Alfresco: OCR, AI, Whisper, PII Redaction and More in Alfresco Blog
